Since November of 2019, Nick Amlag and I formed a video game studio and shipped Breakpoint, a twin-stick action game with exploding melee weapons. It released pretty recently, so go check it out!
Breakpoint is an arcade game centered around chasing high scores. The leaderboard is centrally important, providing players the reason to play the game - to better their own scores, and to surpass others. The sanctity of the leaderboards is critical to ensuring that players feel that the game is fair. If cheaters begin showing up on the leaderboard, confidence erodes, and players feel that there’s no point in chasing high scores of their own.
The in-game replay system is our solution to this problem. Replays ensure fairness by allowing any player to check the validity of another player’s scores. Simply by clicking on another player’s name, they can instantly start watching the replay of that player’s high score run.
Players can also learn new strategies from others using the replay system, too, turning negativity to positivity at the end of a run. It changes “How the hell did that player get eleven million points? I can never get there!” into “Oh, okay, so that’s how they did it, let me give it another try!”
These two benefits - serving as an anti-cheat and getting players un-stuck - provide a huge benefit to Breakpoint. Of course, I need to credit to Dustforce and Devil Daggers, the games which gave me the inspiration to implement this feature into our own game.
So, now that I’ve covered they why, let’s get into the interesting part - the how.
High-level Details
The Replay Format
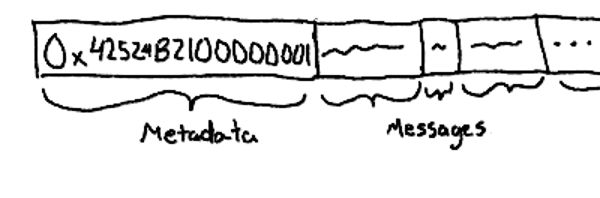
Every replay file begins with a metadata header describing the contents of the file. The only things in this metadata are a 4-byte magic string, followed by a 4-byte version number so we can keep backwards compatibility with old versions.
Immediately after the metadata, replay data begins. The replay data is simply an array of replay messages consisting of (1) a message type, and (2) the message data.
Example message types include EntityMoved, PlayerDamaged, and PowerupPickup. Data for the EntityMoved message includes an identifier indicating which entity moved, along with its new position and rotation:

Other message types contain other data, depending on the type. For instance, PlayerDamaged only has one piece of information, the entity ID of the enemy which damaged the player, so that we can highlight that enemy during the death slo-mo.
Replay messages are not byte-aligned, and they are fixed in size (though that size may differ based on the replay version). These two properties allow us to very tightly pack the messages. For instance, we pack enums with four values or less into two bits, and flags into just one bit. If that means a message is 7 bits and doesn’t end at a byte barrier, oh well - just use the next bit for the beginning of the next message.
This does mean that one bug in replay reading is catastrophic. Once we become misaligned with the replay messages there’s no marker from which to recover - it’s just a bunch of bits. However, this allows us to save a lot of overhead which would otherwise be used for padding.
Replay Submission
The replay encoder is always listening for events while the game is running. When an event that it cares about occurs - for example, when the player is damaged - it immediately records the event to an in-memory buffer. At the end of every FixedUpdate, the replay encoder writes a special message type, the FrameBarrier. The next FixedUpdate, it does it all over again.
Finally, when the player receives their final death, the replay encoder writes an EndOfStream message and flushes the buffer. Right after that occurs, the player’s score is submitted to the backend. The backend, in this case, is an Azure Function with an HTTP trigger.
when score submission occurs, the replay is not submitted immediately. First, on the server-side, your submitted score is checked against your previous high score. If your submitted score is lower than your previous high score, then no replay is needed, and the Function simply returns success. If your new score is higher, then the Function returns an error - REPLAY_NEEDED - which tells the client to submit the same request again but with a replay.
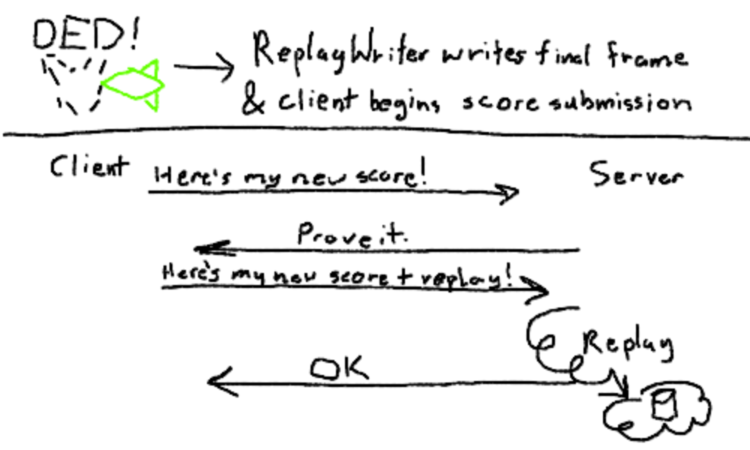
Note that this flow is stateless on the serverside. The only rule that the server enforces is “if you submit a new high score, you must upload a replay.” It doesn’t care whether the client had tried and failed before.
Once a replay is received, the Function uploads it to Azure Storage container. The file is keyed off the player’s ID, along with whether the replay is a normal mode or hard mode replay. If a file is already present, it’s simply overwritten.
Replay Playback
The container storing the replays is writeable only by the Azure Function, but it’s publicly readable. When a player requests a replay, all they’re doing is sending a normal HTTP request to the Azure Storage backend to download a file. The file’s name is keyed off the player IDs of the players on the leaderboard, and we’ve already retrieved those when we got the leaderboard data. I didn’t need to write a single component myself to manage this.
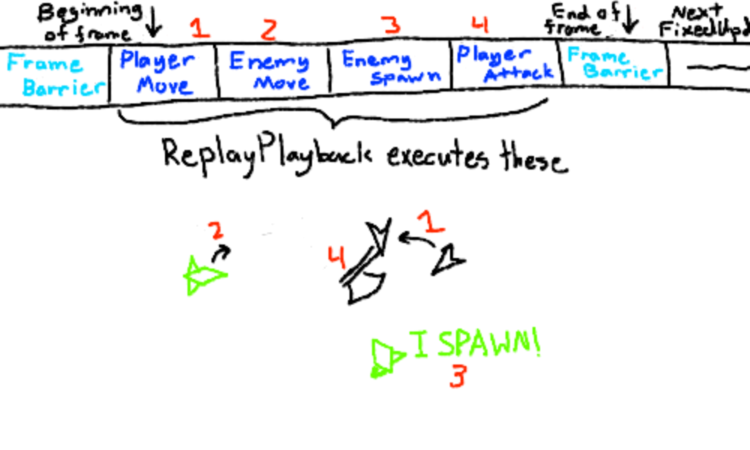
Replay playback ends up being fairly simple with the replay schema we’ve set up. We take the player to a special Unity scene which has a player entity with input disabled. Any enemies we spawn in this scene have their normal behaviors disabled or semi-suppressed.
Then, every FixedUpdate on the playback side, the replay playback engine reads the replay like a tape, executing each event until it finds a FrameBarrier message. Then, it waits until the next FixedUpdate, repeating this process until it finds an EndOfStream message, indicating there’s no more events to be read.
Server Costs
Using these components has been incredibly cheap. We’ve paid about $1 for the Azure Function (mostly for my excessive logging), and none yet for the storage. Estimating ahead using the costs on the Azure Storage pricing page, it will remain pretty cheap even if the game explodes in popularity:
\[2\text{MB} \times 100,000\ \text{files} = 200,000 \text{MB} = 200 \text{GB} \\ 200\text{GB} \times $0.01/\text{GB}/\text{month} = $2\ \text{per month}\]Note that I’ve used 2MB for the replay size, but that’s a worst-case estimate: our #1 replay spot at this moment has a replay size of about 2.5MB, but most people’s replays are around 500KB.
Replay Format Details
Let’s get deep into the replay format, because there’s a lot of interesting stuff to talk about here. This section’s gonna be pretty dry because I couldn’t come up with any drawings - sorry!
Honestly, when first musing about replays, I wasn’t sure if they would be practical to implement. Most replay systems I’ve come across record a player’s inputs, and then replay those inputs later to get the same output. This method ensures that replay file sizes are extremely small.
Unfortunately, this system relies on the entire game simulation being deterministic. Breakpoint relies heavily on Unity’s built-in systems - we built the core gameplay in about 3 months, after all - which are not deterministic. Playing back a player’s inputs will produce different results on different computers.
Instead, our system relies on recording game state every frame. That means recording the positions & rotations of every entity, every frame, which is a lot of data to record. Doing some very back-of-the-napkin calculations, we can estimate how much the naive approach would use in a worst-case scenario:
- Use two floats for the position and one for rotation angle. That’s 12 bytes of data every frame per entity.
- Runs, in my experience, could last up to 700 seconds. If we record at 20 frames per second (Unity’s default fixed update rate), that’s 14000 frames of data.
- Enemies can get up to large numbers near the end of the game, maybe 200 darts at a time. Let’s just handwave an average of 50 entities on screen at any time.
That comes out to:
\[14000\text{ frames} \times 50\text{ entities} \times 12\text{ bytes}/\text{frame}/\text{entity}\\ = 8,400,000\text{bytes} = 8\text{MB}\]Which is not terrible, but I knew we could do better. I’d implemented some networked transforms for an RTS using GafferOnGames’ excellent article on snapshot compression in the past. I used many of the same techniques to compress Breakpoint’s replays.
Frames & Interpolation
Unity’s FixedUpdate still runs 20 times per second in the actual game, but entity positions are only recorded into the replay every third frame. On the playback side, I use a simple linear interpolation to interpolate between the entity’s previous position and its position three frames in the future.
Gaffer uses Hermite interpolation in his article, but I found that adding velocity into the payload was more costly than it was worth. If you pay attention to the projectile trails in a replay you’ll notice that they tend to wobble a bit, but otherwise linear interpolation does a good enough job.
Vector Quantization
When recording entity positions, the easy thing to do would be to use a float, which can store values anywhere from \(-3.4 \times 10^{38}\) to \(3.4 \times 10^{38}\). When our arena is 16 world units long, we really don’t need that entire float range.
Instead, we can use discrete values to approximate the values for the entity positions. For instance, if we want to record an x-coordinate within Breakpoint’s 16-unit arena with a precision of 0.1, we’ll need 16 / 0.1 = 160 values. We can map each of those values to an integer:
- 0 => 0
- 1 => 0.1
- 2 => 0.2
- …
- 101 => 10.1
- …
- 159 => 15.9
Then, when we store the position of an entity, we round each coordinate to the nearest multiple of 0.1 and then store that position as a pair of integers. For instance, (1.78, 10.81) is close to (1.8, 10.1), which would map to (18, 101). Then, since we know there’s only 160 possible values, we can store those two integers using 8 bits each (because 2^8 is 256), giving us a total of 2 bytes for a single entity’s position.
If we were to store that same coordinate using two floats, we’d have used 8 bytes, so this way we save 6 bytes per position we store. Of course, we sacrifice some precision, but the difference between 1.78 and 1.8 is imperceptible to the player.
Delta Encoding
We can do even better than storing the absolute position of each entity every frame. Since we know the playback side will know the previous position of the entity, we can encode the new position as a difference between the new position and the previous one. For instance, if an entity was at (1.8, 10.1) and is now at (1.6, 10.9), we can store (-0.2, 0.8).
This gives us a huge gain when combined with quantization. Because we know our entities can only move a small amount every frame, we can shrink that 160 possible values from above down to something more like 10, allowing just four bits per position component.
There’s two things I should note about our delta encoding implementation:
- During replay recording, I keep track of where the playback engine would think each entity is and delta-encode off that position, rather than off the real previous position. This prevents errors from accumulating over time with the approximation from the quantization.
- Sometimes, during an explosion, entities fly so fast that the magnitude of the movement exceeds the range of the delta-encoded version. I use a non-delta-encoded
EntityMoveAbsolutemessage type for those cases (versus theEntityMoveRelativedelta-encoded version).
Other Compression Tricks
Entity move messages take up the vast majority of the messages in a replay, so that’s where our biggest gains were. However, there’s a bunch of other tricks I want to mention too…
Variable-length Encoding
The difficulty in Breakpoint ramps up drastically after five hundred seconds in the arena. There can be a lot of entities on the field at at that point, so our max entity identifier value needs to be perhaps around a thousand. However, for the first five hundred seconds of gameplay, there’s usually less than a hundred entities on the field, so it would be a waste to always record a ten-bit identifier for every entity move event.
To solve this problem, we make use of a simple variable-length field, where the first bit indicates an extended length. If the first bit is set to zero, we record the integer using a short length; if the bit is set to one, then we use some longer length. The replay writer detects how many bits the input value requires and automatically sets the value accordingly. For entity IDs, the default length is 8 bits and the long length is 11 bits.
Is this really worth the complexity? This trick sounds like a lot of hooplah for two bits, right? I took the top replay on the leaderboard and gathered some data. There’s 763835 messages containing entity IDs, and 755624 (or 99%) of those entity IDs have a value of less than 256. That’s 184KB saved off of a 3MB replay.
Variable-length Encoding, #2
There is another variable-length encoding scheme we use which I haven’t seen used anywhere else. This one is used in message types. As there’s only 12 message types, using the above scheme would be wasteful; we’d likely use more space on the extra flag than we’d save. Instead, we use the following scheme:
- If the value “V” is less than 3, encode V as a two-bit value.
- If V is 4 or above, encode a 3 (
11). Then, encode V - 3 using 4 more bits (for a total maximum value of 18).
With this encoding scheme, a balance must be struck for it to be worthwhile. For message types are 3 or above, we are actually wasting space because we’re encoding them using 6 bits instead of 4, but for message types 3 and below we save 2 bits. I chose the message type values carefully: 0, 1, and 2 correspond to EntityMove, PlayerMove, and FrameBarrier respectively. These three message types make up about 95% of all messages. In that replay I mentioned above, this trick saves about another 150KB.
Traditional Compression
Once the replay’s actually done, I run it through traditional compression, in this case GZip. Since we’re not operating on byte boundaries, our data looks pretty noisy, so it doesn’t compress very well. With that example replay I mentioned above, it shaves off about 600KB. Appreciable enough, and though there’s a cost in running GZip in real-time, it seems mostly negligible after I implemented the next trick.
Stream Buffering
We write our replay messages to an in-memory buffer. The in-memory buffer gets flushed to disk every so often to keep our memory footprint low. As far as I could tell, there wasn’t anything to do this for me in C#, so I wrote my own. You can find it at the end of the article.
Closing Thoughts
The biggest pain points I ran into with this system was debugging issues. With such a tightly-packed data format such as this, it’s really hard to open up a replay and pore through it, looking for issues. Instead, I had to write some tools for debugging. This is where Unity’s usefulness really, really shines. With the help of Odin Inspector, I was able to code up this debugging window less than a day:
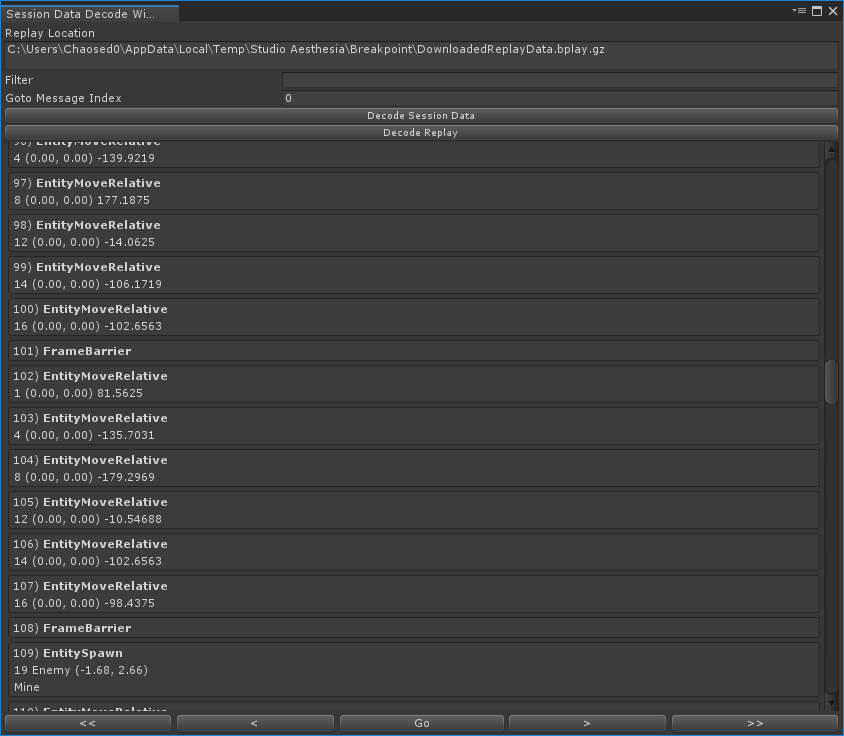
Even with this tool, debugging was a huge pain in the rear. Tracking down all the little instances where entities would become desynced, or when one bit was unaligned, took weeks to debug.
There are a few weird things that you might be able to notice, even now, if you watch closely during a replay. The biggest one is that the player’s attacks sometimes kills enemies it hasn’t yet swept through, because my movement interpolation is not implemented perfectly.
Despite all that, I am very happy with the result I was able to achieve given this approach. The system has been running happily in production for about a month now and I haven’t heard any complaints. Granted, our playerbase is fairly low, but I know for a fact a few of our most competitive are scouring the leaderboard replays of their competition.
If you’re interested in reading through some code, I’ve posted a few of the utilities which are used in Breakpoint to encode our replays. Check them out here!