 As a person who works almost exclusively on Linux, it’s hard for me to understand z/OS. It all just seems so… inelegant. That being said, though, I’m very much a newcomer to mainframe systems, and I’m probably overlooking a thousand and one things that make it better than systems I’m used to. In any case, it’s being used in a lot of places, so it’s not going anywhere anytime soon. Since IHS - the subject of my job - is ported to z/OS, I need to know at least a little bit about working on the OS. I embarked on this journey last week.
As a person who works almost exclusively on Linux, it’s hard for me to understand z/OS. It all just seems so… inelegant. That being said, though, I’m very much a newcomer to mainframe systems, and I’m probably overlooking a thousand and one things that make it better than systems I’m used to. In any case, it’s being used in a lot of places, so it’s not going anywhere anytime soon. Since IHS - the subject of my job - is ported to z/OS, I need to know at least a little bit about working on the OS. I embarked on this journey last week.
The specific issue I worked on was in our code for generating a webpage listing the members of a PDS, a partitioned data set. For those not in the know, that’s basically the equivalent of a directory; a PDS holds several data sets, basically files. I don’t fully appreciate the difference between a PDS and a directory, or a sequential dataset and a file; to me, they are quite similar. Figuring out how to work with them is a bit trickier.
After requisitioning a new z/OS image and building IHS, I was able to ssh into the system, which gave me a nice Unix shell. However, every reference I could find told me to use something called “ISPF” to create the datasets. Luckily, we have a resident z/OS expert who set me on the right path. To access the ISPF interface, I needed to connect directly to the z/OS system through a TN3270-emulating shell. I chose c3270, so I could connect directly through a terminal emulator.
Connecting to the system brought me to some login prompts, which took the same credentials as SSH. This dropped me into the z/OS TSO (time sharing option) prompt. You can execute some different commands in this prompt; I believe you can do everything here that you’d need, but ISPF offers a more user-friendly interface.
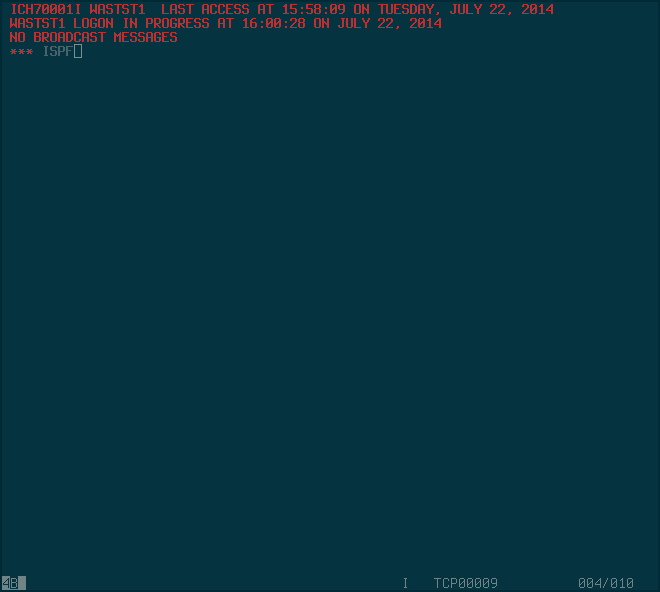 Executing ISPF brings me to a neat console-based menu:
Executing ISPF brings me to a neat console-based menu:
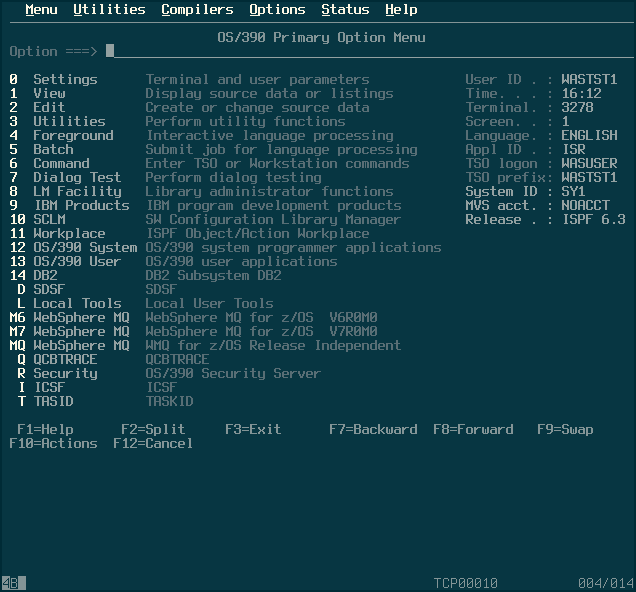 To navigate the interface, you use the “Option” line to select which sub-menu to go into. I wanted to create a dataset, the option for which is located under Utilities -> Data Set. To get there, I entered “3” into the option line, and hit enter; once in that sub-menu, I did the same with option “2”.
To navigate the interface, you use the “Option” line to select which sub-menu to go into. I wanted to create a dataset, the option for which is located under Utilities -> Data Set. To get there, I entered “3” into the option line, and hit enter; once in that sub-menu, I did the same with option “2”.
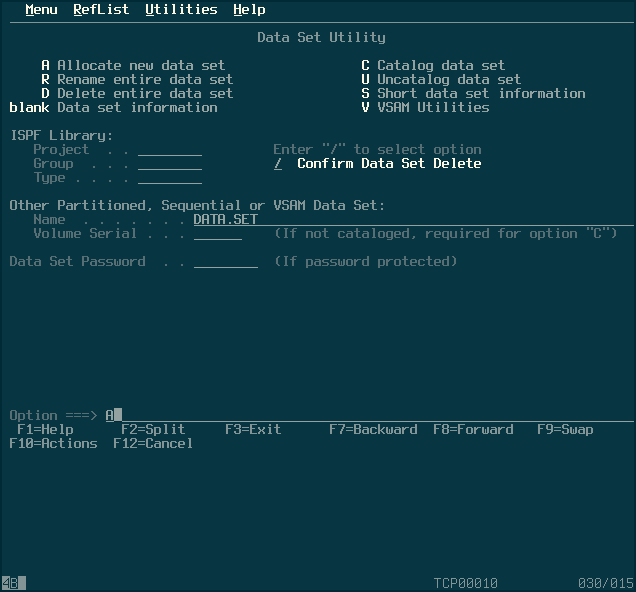
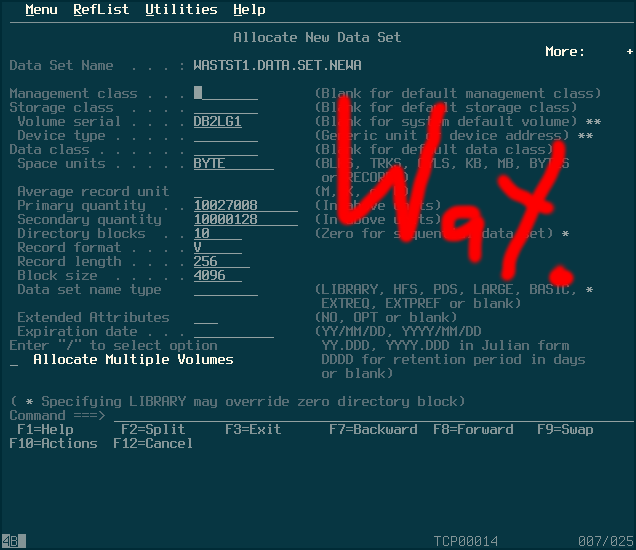
In the above menu, I entered “A” as the option, for allocate, and then entered a dataset name in the appropriate line. Hitting enter brings up a semi-confusing menu of options, some of which I guessed on. The options below seemed to work for me. The important one to take note of is “Directory Blocks”; this is what differentiates a parittioned dataset from a sequential one.
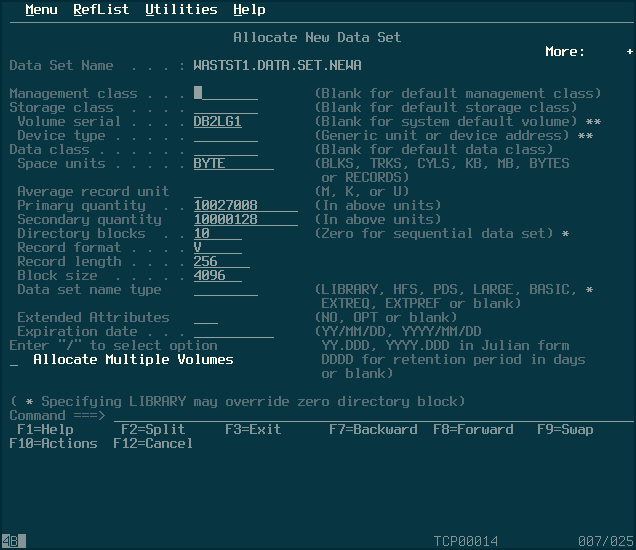 Hitting enter at with the options filled in should allocate the dataset. You can verify by going back one menu (F12) and going into the “dslist” sub-menu. (Most of that is covered in this guide.)
Hitting enter at with the options filled in should allocate the dataset. You can verify by going back one menu (F12) and going into the “dslist” sub-menu. (Most of that is covered in this guide.)
Adding a dataset to the PDS proves a little more tricky. To do so, go back to the root menu using F12 and go into option 2, “Edit”. If you simply enter the name of the PDS you created earlier, it will give you an error about there being no datasets within the PDS - which is true, but spectacularly unhelpful. You have to be familiar with the syntax of datasets, which is basically:
PDSNAME(DSNAME)
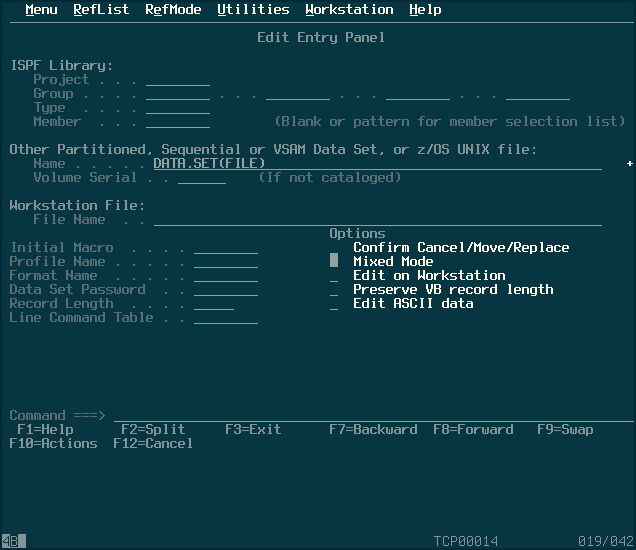 Editing a non-existent dataset in the PDS creates it automatically, so to create a dataset in the PDS, I followed the guide for creating a sequential dataset in that same guide back there.
Editing a non-existent dataset in the PDS creates it automatically, so to create a dataset in the PDS, I followed the guide for creating a sequential dataset in that same guide back there.
This bring you to the built-in ISPF editor. This guide proved handy. To summarize basic usage: enter RESET in the command line to clear any messages (after reading and making a note of them of course), tab down to the beginning of the file, then enter “i” and hit enter to begin inserting text. To exit insert mode, hit enter twice (insert an empty line).
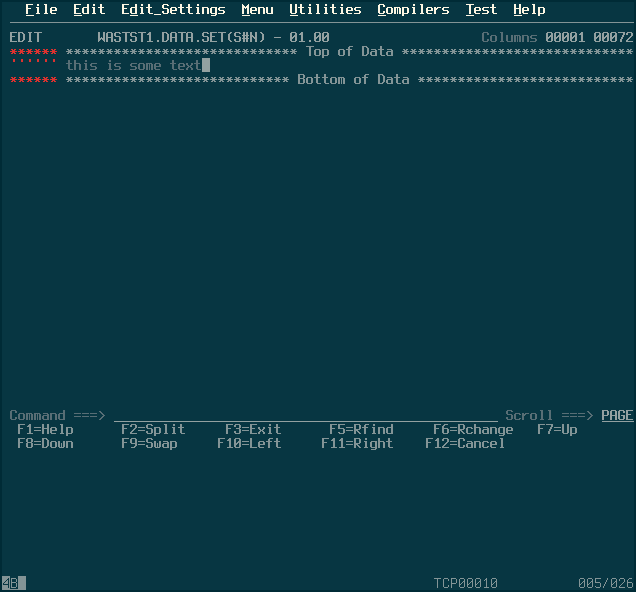 Now you should have a PDS with a dataset in it. Inserting more datasets into the PDS can be accomplished the same way, but now, you can also use the ISPF editor and “edit” the PDS directly; it will now list the datasets within the PDS and allow you to execute actions.
Now you should have a PDS with a dataset in it. Inserting more datasets into the PDS can be accomplished the same way, but now, you can also use the ISPF editor and “edit” the PDS directly; it will now list the datasets within the PDS and allow you to execute actions.
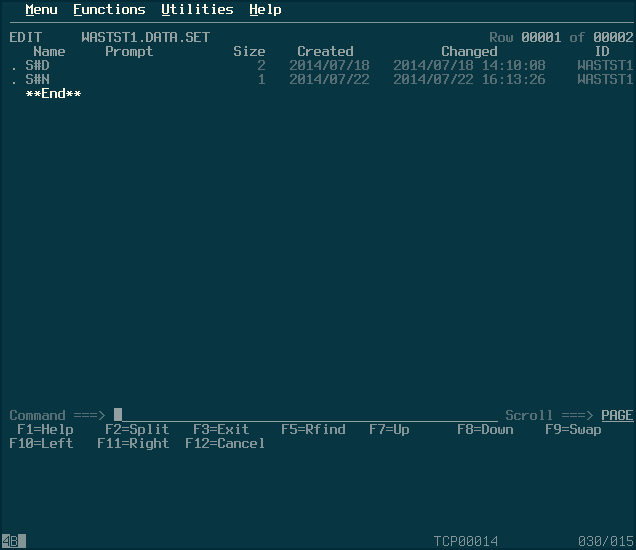 To exit, F12 out to the base menu, then F12 one more time. It will ask you if you want to save your log data set; I always choose option (2), or “Delete data set without printing”. I’m sure there’s a valid reason you’d want to save the log, but I haven’t found a use for it yet. Finally, once back at the TSO prompt, enter “LOGOFF” to exit completely.
To exit, F12 out to the base menu, then F12 one more time. It will ask you if you want to save your log data set; I always choose option (2), or “Delete data set without printing”. I’m sure there’s a valid reason you’d want to save the log, but I haven’t found a use for it yet. Finally, once back at the TSO prompt, enter “LOGOFF” to exit completely.
That’s really all there is to it. I’m sure I’ll be doing more z/OS work in the future, so I’ll post more on it later for any Unix-y people who have to learn the platform.