
I’m Ed Lu, principal engineer on Wizard with a Gun, which released in October 2023. This is the third in a series of articles about the engineering behind the game. Read the previous one, about waterfalls, here.
Creating a networked multiplayer game with only three full-time engineers was extremely difficult. One of the largest challenges we faced was solving state divergences. In this article, I’ll go over what a state divergence is, and how we managed to track down the majority of our divergences before launch.
I’ve tried to abstract away Wizgun’s specific architecture as much as possible, but I go into specifics where necessary. It will help if you are already familiar with networking and deterministic lockstep. If you are in development and trying to solve the same kinds of problems, this info is for you. I don’t want anyone else to have go through the pain that we did.
Deterministic Lockstep
If you are already familiar with deterministic lockstep, you can skip this section.
First, an outline of the problem. What is a state divergence, and why do we care?
The multiplayer model that most games use is called state replication. When something important happens on the server - for example, when a player moves or dies - the server sends a message to the clients telling them about it. The clients then apply that state change to their view of the world.
Wizard with a Gun uses a different multiplayer model: deterministic lockstep. In this model, only player inputs are sent over the network. Instead of the server saying “Player 1 moved this much”, it says “Player 1 has the W key held down”. Then, on the both the client and the server, we run the game simulation as if the player had those inputs held, and the player moves the same amount of distance forward on both sides.
In our deterministic lockstep model we have:
- A game state for frame
N - Some inputs (both ours and other players’) for frame
N - Simulation code
At the beginning of a multiplayer session, the joining player receives the entire initial game state once from the host. Every frame, the host and the client send each other their player’s inputs. The simulation code takes the inputs, modifies the game state, and advances to frame N+1. Then, everything repeats.
To ensure determinism, both the server and the client must have the same game state after running the simulation code, down to the individual bit level. They must be exactly the same. Under deterministic lockstep, even one small difference in the simulation can lead to disaster, and usually begins a spiral from which we cannot recover.
Why is it so important that the game states exactly match? In the below video, the player is fed the exact same input, but the enemy behaves slightly differently on the right vs the left. The timing of attacks is slightly different due to some non-deterministic behavior from one run to another. You can see that what each side sees quickly becomes different, which is no fun.
When this occurs, we call this a “state divergence”, because the game state that the client sees no longer matches the one generated by the host. In a deterministic lockstep model, there is no recovery beyond sending the entire game state again from the server, which is an expensive operation.
Detecting State Divergences
How can we detect when divergences occur? From a player’s perspective, it’s easy to see that something is wrong. If one player says they are dead, but the other player sees that they are alive, that’s clearly a problem. There ought to be a way to detect this programatically, too, so that we can interrupt gameplay and allow players to report the problem.
We could try compressing the entire game state and sending it over the network. Then, the multiplayer client can compare the received game state to theirs. This naive implementation becomes infeasible in all but the most trivial of cases. Sending megabytes of data ten or twenty times a second cannot be done on most connections, and comparing every byte of the game state takes a lot of time.
Instead, the approach most games use is to periodically calculate a checksum of part of the game state and send that over the network. Upon receipt, the receiver calculates a checksum of their game state, and compares it to the received one. If they differ, then the game states have diverged.
We only checksum part of the game state because the running the operation over the whole state can be very expensive. In Wizard with a Gun, we chose to checksum the positions and count of entities, because almost every calculation in the entire game indirectly ends up modifying an entity’s position, creating an entity, or destroying an entity.
Solving Divergences
With the checksumming method above, we can detect state divergences, but fixing them is much more difficult. When we see that our checksums mismatch, all we know is that something is different… somewhere. Checksums are not reversible, so we have no idea what is different, only that something is different. How can we track down what diverged, let alone what section of code caused it?
Checksum mismatches were the bane of our engineering team’s existence for the entirety of Wizard with a Gun’s development. Any time one came up, we would issue a collective groan, and an engineer would spend somewhere between two days to a full week tracking down and solving the issue.
There are two major sections to solving every state divergence:
- Finding a reproduction case
- Drilling down to the root cause of the problem
Note that, for divergences, reproduction cases involve both client and host. We must reproduce both sides of the divergence; that is, we must be able to reproduce both the game state that the host saw, and the game state that the client saw.
Finding a reproduction case ends up being the harder problem by far, so let us first assume that we have found a reproduction case and talk about tracking down root cause.
Finding the Root Cause
Without good discipline and tooling, finding the root cause of a divergence is very difficult. There were usually no easy clues about what was going wrong. Even when we saw a problem, a visual confirmation of a bug did not indicate that the root cause was anywhere near the related sections of code.
To take a real example: we ran into a pathfinding divergence where an enemy would decide to take a path in one direction on one computer, and in a different direction on another. This could have been caused by all sorts of things - mis-application of physics, a bug in the pathfinding code, etc. Our investigation ended up taking us to a non-obvious place: the system that calculates the areas of static obstacles. These obstacles were being calculated differently on the host and the client, which was causing enemies to take different paths.
There are many, many examples like this where a divergence would occur somewhere deep in our simulation, and only become detectable after making its way through many systems. For this reason, simply looking at a reproduction case and trying to deduce what was occurring in the code was almost always a dead-end.
To do better, we need a more systematic way to narrow down the cause of the divergence. As I mentioned before, the checksum is not very useful by itself. We only compare checksums at the end of every frame, so when we see a checksum mismatch, any piece of code that ran during that frame could have contributed to the divergence.
To narrow the search space, we introduced a “checksum trace” flag. When this flag is toggled, a checksum is calculated very frequently throughout the frame and logged to a trace file, along with what section of code had just run. For us, “very frequently” means that a checksum is logged after each system in our ECS.
To find the root cause of a divergence, we follow these steps:
- Run the reproduction case with tracing on. Remember that a reproduction case involves both host and client, so two traces are generated.
- Run a diff algorithm on the two generated checksum traces.
- Find the first system after which the game-state checksum differs.
- Add logging and repeat.
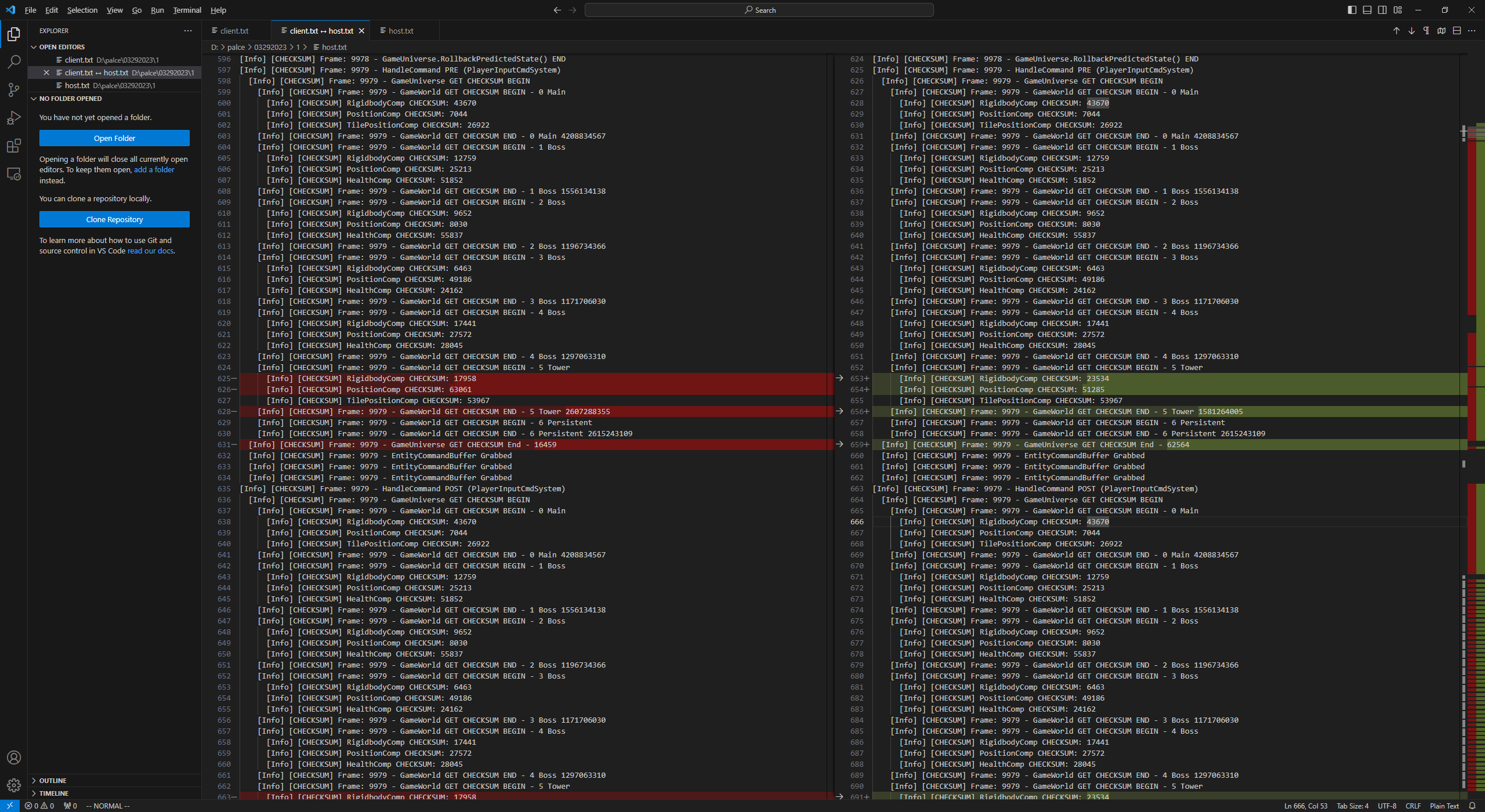
Below is an example diff of two of our trace files in Visual Studio Code. This trace shows that the checksums for the RigidbodyComp and PositionComp are mismatching after RollbackPredictedState.
Running this process would often take a full day for an engineer. It’s quite painful. The checksum trace makes the game run slower, and reproducing both sides of the divergence requires running the game twice. But the real kicker is that we have to run these steps many times to track down the root cause. Why is this? After all, the checksum trace shows exactly which system caused the divergence, right?
Remember that we do not checksum the entire state. We only checksum the positions and counts of entities, for performance reasons. Because of this, the trace only shows what system last modified the diverging entity’s position, or created/destroyed the diverging entity, and not which downstream system caused the change.
For instance, when we debugged the pathfinding divergence above, we had to repeat the steps three times:
- Diffing the checksum trace initially showed a divergence in physics update system.
- We added tracing to report all physics updates that are enqueued, and which system they came from.
- We ran the checksum trace again.
- The checksum trace showed that the pathfinding system enqueued a physics update for entity ID
Ewhich went in one direction in one trace, and a different direction in the other.- We added tracing to the pathfinding system that recorded details of entity
E’s pathfinding calculation - We ran the checksum trace again.
- We added tracing to the pathfinding system that recorded details of entity
- The pathfinding traces showed that there was a static obstacle on the host that was not on the client.
- We added more tracing to understand why one side generated a static obstacle and not the other.
- We ran the checksum trace again.
- Finally, the checksum trace showed the root cause: a bug in the calculation of static obstacle locations.
We call this step “log-drilling”, because it’s about drilling down from the proximate cause of the divergence (entities are in the wrong position) to the true root cause (static obstacle is incorrectly calculated).
Following this process over and over again, for many different divergences, allowed us to speed up the process. A big win for us was understanding that there were lots of shared places through which divergences would propagate. For instance, position updates almost always propagate through the physics update system. We added permanent tracing to that system, often allowing us to skip one iteration in the loop. Other common places where we left tracing were in world generation and ECS component addition/removal.
Reproducing State Divergences
As mentioned above, log-drilling can only be useful if we are able to obtain a reproduction case. This is far more easily said than done. Far, far more easily.
If you are about to read this section, buckle up - it is long and dense because it spans a large portion of Wizard with a Gun’s architecture.
Near the start of the project, finding a reproduction case was purely ad-hoc. There was no established method. An engineer would take whatever data was available - logs, replays, videos, QA reproduction steps - and try, sometimes for a full day, to see if we could track down a reproduction case for the mismatch. Often, we would never find a reproduction case at all, and we would have to move on to something else, leaving multiplayer in a semi-broken state.
This was a crisis for the engineering team. Multiplayer is a core pillar for our game, and if we couldn’t get it working, our publisher would be quite upset. It was too late to transition to a different network model. To add on top of this, the lead engineer had left the project about four months after I joined, which left a gaping void in the team’s knowledge.
Soon after I joined, I had a hard think on how we could solve these divergences more quickly. To start with, I had to answer the question: how do state divergences occur?
Floating Point Math
It is common knowledge among programmers that floating point math is not necessarily deterministic. Resources on the internet all suggest this with varying degrees of severity. For more information, Bruce Dawson’s and Glenn Fiedler’s articles are good primers.
This was scary for us. We carefully chose some constraints to lessen the risks of float math divergences: we ruled out console cross-play, and we run all of our simulation code under Unity’s Burst compiler. Still, the spectre haunted us. A true floating point divergence based on machine configuration would be a show-stopper for our networking model, and would require us to rewrite a lot of our basic math functions.
However, as we solved a few state divergence issues, it became clear that floating point math was not our main problem. In fact, up to this point, not a single divergence we’ve found is caused by floating point math. Now that we’ve released to a wide audience and have more data, it doesn’t look likely that it will ever cause widespread problems.
Causes of Divergences
If not floating point math, what does cause our divergences? For us, it’s always programmer error. As we solved more and more divergences, we found that the mistakes we made would usually end up in three categories:
- Differences in initial state
- Issues stemming from multithreaded jobs
- Predicted state leaking into our game state
Differences in Initial State
Recall that determinism requires that we obtain same result given the same inputs and the same initial state. If the initial state is at all different, then we will immediately diverge.
The ECS in Wizard with a Gun is constructed such that almost all of our game state can be packed into a single array of contiguous bytes, which can be sent across the network to clients when they join a game. This has huge benefits. Engineers don’t usually have to concern themselves with ensuring that any state they modify is synchronized to clients.
However, there are some instances in which we compute data upon start up and depend on that data converging to the same initial state, usually for performance reasons. For instance, our static pathfinding data is dynamically computed by host and client, rather than being sent over the network. Sending that data would largely be a waste of resources.
There are other data, too, that aren’t part of our ECS but need to be synchronized. For instance, we allow the host to choose skip the tutorial. When spawning players for the first time, we equip them with a starting weapon if the tutorial is skipped. If this flag is not properly synchronized to clients, the game state will diverge when the player attempts to shoot.

The more sources of initial state there are, the greater the chances that some engineer messes something up, and Wizard with a Gun has a varied assortment of them.
Determinism under Multithreading
Wizard with a Gun uses Unity’s jobs system. This is a system that takes sections of code and schedules them across multiple threads. Jobs can run concurrently with other jobs, and jobs can also run concurrently with themselves if it is safe.
Fortunately, Unity ships a set of safety checks with the jobs system to guard against common race conditions, such as reading or writing from the same containers in two different jobs that may run concurrently. It’s quite a magical thing, and saved our team from the vast majority of self-inflicted concurrency issues.
However, there is one crucial class of problem that we ran into. If a job runs in parallel and makes use of containers that allow concurrent writing, we cannot use the contents of that container until they are sorted in some deterministic manner.
The below profiler session shows that the work done by EntitiesOccupyingSystem.GatherEntitiesToUpdateJob is split across multiple threads (for performance reasons). All the threads enqueue to the same container, a NativeQueue. Once all the threads are finished writing, the UpdateMapJob runs, which processes the results of the threads.
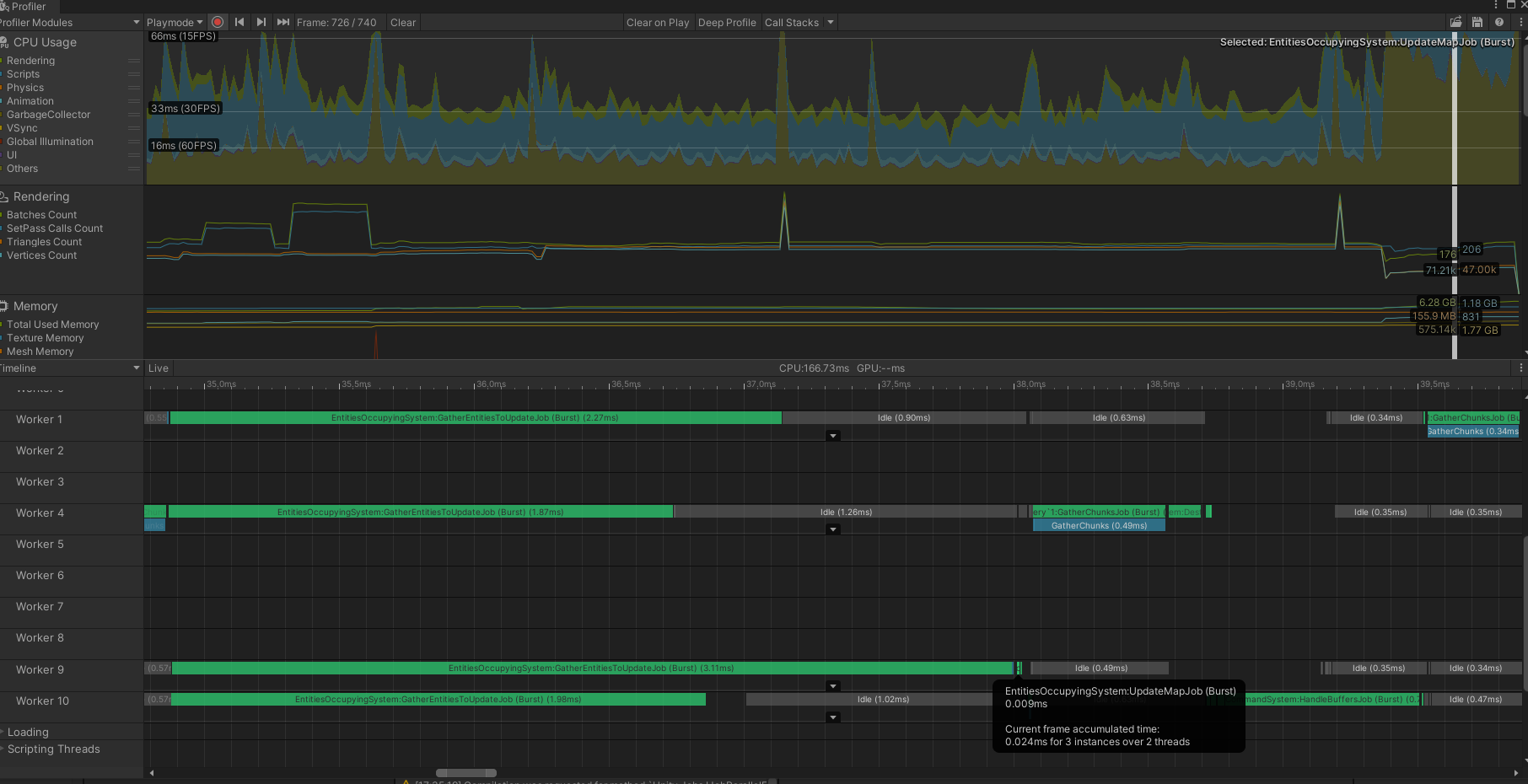
The details of thread timings are completely dependent on the conditions of the CPU, OS and even the other programs are running on the system. There is no guarantee when, or for how long, or in which order, threads will run for a given system, so the final result of concurrent writes can be in different orders on different systems - a potential source of non-determinism.
To combat this, after these kinds of jobs are complete, we sort the container based on some stable thread ID. For us, this is most commonly the index of the ECS chunk that has been passed to the thread, but the ID can be anything as long as it is deterministic across threads.
Unfortunately, this turns out to be an error-prone solution. The onus is on engineers to recall that whenever a parallel container is used, we must sort the results before using them. Forgetting to do so resulted in a couple divergences where an engineer forgot to sort, and at least one where we sorted by a non-deterministic ID.
Two details also bear mentioning:
- In our ECS, entity ID cannot be used as a deterministically stable ID. Entity IDs in our ECS are non-deterministic because we allow creation of ECS entities in concurrent jobs, meaning the IDs are thread-timing-dependent.
- Our deterministic sorting method sorts first by thread ID, but if two entries’ thread IDs are the same, then it falls back to sorting by index within container. This is important because if entries within the same thread have the same ID, but are stored at different indexes, sort algorithms will not always enforce that they will end up in the same order.
Predicted State Leaks
A Basic Rundown of Prediction
This section gives a very basic description of rollback & prediction as applied to deterministic lockstep, but you can find more comprehensive resources around the internet. If you are already familiar with the concepts, you can skip to the next section.
Once again, recall that determinism requires three things: the same initial state, some deterministic simulation code, and inputs to the simulation. Since we are receiving other players’ inputs over the network, we do not always have all the input to the simulation available. Network delays mean that we have to wait for some time before we receive packets from other players for the current frame.
For this reason, the deterministic lockstep model enforces a delay between receiving local input and feeding that input into the simulation. The hope is that, by the time the input is fed into the simulation, we’ll have waited long enough that we’ll have received all inputs from all clients for that frame.
Under a naive implementation, there is a several-frame delay between when a player presses a key and when the corresponding action takes place. This can be very detrimental to game feel. Movement, in particular, feels bad with anything above a 30ms delay.
For this reason, we employ a strategy called “rollback and prediction” (or just “rollback”). Generally, the strategy looks like this:
- Simulate forward one frame (the “current” frame) with all players’ inputs
- Save the current frame’s game state
- Simulate forward multiple frames (however many frames our network delay enforces) given any inputs we have received
- Visually display the frame
- Roll back to the saved game state for the “current” frame
- Repeat
This way, the player always sees their actions play out in real time, with minimal disruption. If an action occurs which contradicts the state seen by the player, it’s fine - when we roll back and re-simulate, the state will then resolve to the correct one.
Prediction and Determinism
In Wizard with a Gun, we employ a limited version of prediction and rollback. Our simulation code is complex enough that simulating all entities even twice per frame can be prohibitively expensive, so it’s out of the question to predict the entire game state.
Instead, when predicting forward, we run only the systems that affect the local player - movement, dashing, physics, and so on. And when we save & rollback, we do so only for the player’s data.
In the below image, the player attempts to shoot on frame 1. in the non-predicted scenario, the shooting animation occurs four frames after. However, under prediction, the animation occurs immediately.

I’ll talk more about the benefits and drawbacks of this system someday, but for now, let’s focus on the consequences to determinism.
Since we save & rollback only the local player’s data, if code running under prediction happens to modify non-player-related data, then we will have introduced non-determinism into the simulation. To illustrate why, let’s take a look at the shooting example above. The projectile entity always spawns on frame 5, whether prediction is on or not. Why is that?
Imagine that the prediction system also spawned the projectile on frame 2. It would certainly feel more responsive to do so! However, since we roll back only the player entity, the projectile entity would remain after rollback. On any peers, the projectile would not have been spawned on frame 2, because they would not have yet received our local input that would have spawned the projectile. Their view of our player would look like the “prediction off” row. After the packet clears network delay on frame 5, they would process our input and spawn the projectile. This is clearly a state divergence.
Since we often want to share code between predicted and non-predicted systems, these kinds of bugs occur surprisingly often. Whenever we write a system that modifies some property related to the player, and we want that change to appear responsive to the player in multiplayer, we need to be very careful to only modify state that will be rolled back.
Engineering discipline
If your head is spinning, don’t worry. Mine is too, even after three years of handling these bugs.
Before we dive back into reproduction cases, I want to quickly emphasize the effort that went into finding the categories above. As I mentioned before, solving divergences was incredibly ad-hoc at the start. As we started solving a few, I put forward the idea that our team should start categorizing and learning from our previous efforts. There was no point in solving one divergence if we couldn’t figure the rest out.
The engineering team agreed to do small writeups on each and every divergence we found. This allowed us not only to share the info with each other, but also allowed us to build up a corpus of knowledge on how they occur, what strategies were useful for solving them, and how we could make them faster. We often referred back to this document when a new divergence cropped up to remind ourselves of what strategies to use.
I cannot over-emphasize how useful this effort was for us. I’m choosing to publish all of these postmortem writeups to the public. This is in a hope that others may avoid going through some of the same growing pains that we did. See them all here.
Replays
Let’s take a brief foray into something related to determinism, but not immediately related to state divergences.
Since our code is deterministic, we can generate perfect replays of a player’s session at low cost. Without determinism, perfect replays are only possible by writing the entire game state to disk every frame, which is prohibitively expensive both in terms of disk space and computation time. With determinism, we don’t need to save the entire game state. As long as we save initial game state + inputs for all previous frames, then we can re-generate the exact game state for a given frame.
Gathering replays is beneficial for debugging all sorts of scenarios. For instance, when QA files crash reports, they do not need to research and give detailed reproduction steps. As long as they gathered the replay from their last play session, we could get an exact reproduction case for the crash most of the time, even for one-off crashes that were not reproducible by QA.
Using Replays to Solve Divergences
The most reliable method we found to generate reproduction cases for state divergences, no matter the cause, was to use replays. Let’s take a look at each of the three causes mentioned above.
- Replays contain the initial state of the game. If we are able to collect a replay file from both the client and host, then we can compare the initial states of each and find the exact location where the state differs.
- Since running a replay runs the exact same code as normal gameplay, replays will often suffer from the same multithreaded problems that normal gameplay does. When playing back a replay, if the final checksum of the replay’s game state differs from one run to another, it is almost always an indication that we have an issue related to thread timings.
- At first, replays did not implement prediction and rollback. After all, prediction is dependent on having a local player, and replays do not naturally have the concept of a “local” player. However, we quickly realized this was a missed opportunity. We allowed replays to pretend there is a local player, and started predicting that player forward. If we run a replay predicting one player, receive one checksum, then run the same replay but predict a different player, and receive a different checksum, then the divergence is likely due to prediction.
Standardizing these methods of obtaining reproduction steps was a huge win. Ad-hoc reproductions, without any procedure, can be incredibly frustrating and lead to human error when trying to track down the root cause. Once we stabilized and improved the infrastructure for replays, we cut down this frustration quite a lot, allowing us to solve divergences more effectively.
State divergences in Replays
Unfortunately, maintaining the replay system also requires constant vigilance. Since replay validity is itself dependent on determinism, we often ran into situations where the replayed game state would diverge from the game state the replay was meant to reproduce.
In addition to player inputs, replays contain the game-state checksum for each frame, calculated by the player who generated that replay. When running a replay, the simulation is fed the recorded inputs, and then we compare the recorded checksum to the one that is generated by the replay game state. If those checksums do not match, then the replay diverged from the state that the player observed.
To debug these divergences, we use the same steps as we do for a real divergence: find a reproduction case, then run it repeatedly under checksum tracing, adding tracing until we drill down to the root cause.
Often, these mismatches were caused by bugs that would have caused a divergence under real conditions, too. But just as often, the divergence would be a result of some code that was ifdef‘d behind the UNITY_EDITOR compiler define, or a similar problem. For this reason, we eventually added a way to play replays in a standalone build, in addition to the Unity editor.
Running into these replay divergences was incredibly frustrating, because it would often happen while trying to debug a mismatch observed by a player. The engineer would have to drop what they were doing, fix the replay divergence (which would often take several days), then finally return to the original bug they were trying to solve (which would also take several days).
It is tricky to evaluate when to prioritize improvements to internal tools, like the replay system, versus prioritizing time to work on game features. Our team of three handles it all, which means sometimes our tools are not fun to use, or they break, which can again lead to frustration and inefficiency when solving issues.
Riding this line was a challenge throughout the entire project, and we’re still learning. I see the maintenance of the replay system as necessary work that we had to simply roll up our sleeves and get done. Without the replay system, there was no systematic way to debug state divergences. This extra vigilance wore on the engineering team, but in the end, it was absolutely worthwhile.
The Checksum Mismatch Playbook
Finally, given all this information, we can put together a coherent strategy for tackling checksum mismatches. I call this the “checksum mismatch playbook”.
To obtain a reproduction case:
- Gather a replay from an instance of the game when the mismatch occurred.
- If possible, gather the replay from both host and client, which can be useful in some circumstances.
- Attempt to run the replay with prediction.
- Run the replay, faking prediction as the host. Record the checksum obtained on the mismatching frame.
- Run the replay, faking prediction under the client. Record the checksum obtained on the mismatching frame.
- If the checksums differ, it is likely that the issue is caused by prediction. You now have a reproduction case - move on to drilling the trace.
- Otherwise, try running the replay repeatedly, keeping an eye on the checksum obtained on the mismatching frame.
- If the checksum sometimes matches what is stored in the replay, but not other times, then it is likely you have a frame timing issue. You now have a reproduction case - move on to drilling the trace.
- Otherwise, artistic methods are required. See the next section.
To find the root cause of the divergence given a reproduction case, we drill the checksum trace:
- Run the reproduction case with tracing on. Remember that a reproduction case involves both sides of the divergence.
- Run a diff algorithm on the two generated checksum traces.
- Find the first place where the game-state checksum differs.
- Add logging and repeat until you find the exact section of code that is causing the divergence.
When the Playbook is Not Enough
The playbook has been enough to solve many of the divergences that come up. However, sometimes, you run the playbook, and you simply fail to come up with a reproduction case. In these cases, we fall back to ad-hoc investigation. Take a look at all the available data - logs, replay, video, QA reproduction steps - and try to deduce what you can given the knowledge you have.
If you look through the list of divergences we’ve solved, you’ll see that most of them fall into the three categories I listed. However, there are a number that we reproduced using unconventional means. To give a couple examples:
- One divergence was caused by players in multiplayer having different system languages set, which caused sorting orders of systems to diverge. This would never have been caught by a replay. We simply looked at the system languages provided by the user reports, came up with a hypothesis, and it turned out to be true.
- Another divergence was caused by a thread timing issue, but it was resistant to running the replay multiple times. The replay would only produce a mismatch once every few hundred runs, which was not enough for us to be confident that it was a thread timing issue. This ended up being solved by pure intuition.
In my opinion, the most important step in solving these is not the solution itself. It is to stay diligent and keep thinking of ways to improve the tooling such that the reproduction case would have been more obvious or more quickly found. It’s never about solving the current bug; it’s about solving the next one, and then the next one, and then the next one.
Conclusion
State divergences fall into a terrible intersection of properties:
- If not fixed, they are incredibly disruptive to the player’s experience.
- They require a herculean amount of effort to fix.
- Once fixed, the effort involved is completely invisible to the player. The game working as intended is not an apparently exceptional feat.
My worst fear leading up to release was that we’d missed a widespread state divergence that disrupted multiplayer. Players would not have been very forgiving, and it would have taken us several days for any kind of patch turnaround. This did not end up happening. The divergences that were reported were all rare, and were solved by the engineering team within weeks.
There’s this sentiment around the industry, said half-jokingly and half-reverentially, that each and every video game is a miracle. That we were able to ship Wizgun with very few multiplayer issues, with such a tiny engineering team, while working on a game that was challenging in so many other ways, is certainly a miracle - but it is also a result of tons and tons of hard work and diligence. I’m proud of what we accomplished.
Credit to CJ Kimberlin who is the original Lead Engineer of Galvanic Games, and the one who initially built all of the architecture upon which this article is based.
Huge thanks to Rick Hoskinson for writing his series on Riot’s Project Chronobreak, and for discussing Wizgun’s challenges with us.
I hope this article helps others going through the same challenges. If you’re one such person, don’t hesitate to reach out to me at chaosed0@gmail.com.